Architecture overview of “boxes and glue”#
Here is an attempt go give you an overview of the “boxes and glue” PDF typesetting library
There is a high level API (the frontend) and a low level API. Both can be used to create PDF documents. While the frontend gives you ready to use data structures and methods, you can still use the backend and create all the items yourself.
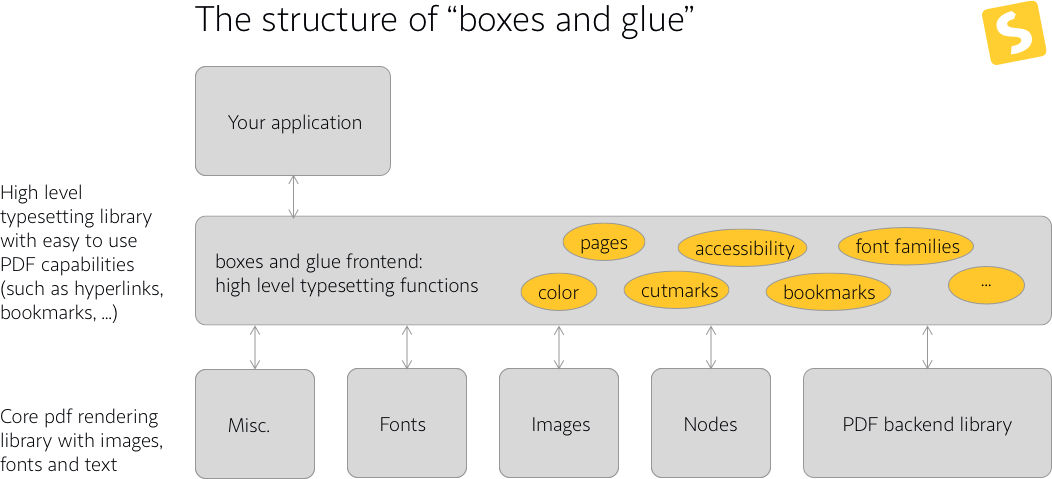
The frontend#
The typesetting frontend knows about these building blocks:
- font sources: A font source represents a physical font file (OpenType, TrueType).
- font families: font families group font sources together to ease switching to different font styles and weights.
- document: This is the main object and represents a PDF document.
- page: A document contains pages and each page has vertical lists (vlist nodes) containing typesetting material.
- text: a text element is a hierarchical data structure which contains paragraphs and font switches and other elements such as hyperlinks.
The backend#
The backend has all low level functions to handle typesetting (basic font loading and accessing, language handling and hyphenation, justification of paragraphs, ...). It also contains the logging API that is used in the frontend can which can be used in the underlying application.
Noteworthy parts of the backend library#
- nodes: The most important part of boxes and glue are items called “node”. A node is a small data unit which can contain for example a letter (glyph), a language information or an image.
- Line breaking algorithm: The famous Knuth and Plass optimum fit line breaking algorithm is implemented in the backend. This also known from the typesetting software called TeX. It also handles hanging punctuation and font expansion.
- Hyphenation: The pattern based hyphenation algorithm by Franklin Mark Liang is part of the boxes and glue backend.